[CS] Operating System - 컴퓨터 시스템의 구성1
Software Engineer에게 필요한 운영체제 기초지식을 학습하자
이 글은 Operating System Concepts을 기반으로 작성되었다.
학습 목표
- 운영체제의 정의를 이해한다.
- 운영체제를 왜 학습해야 하는지 이해한다.
- 컴퓨터 시스템에 구성 중 인터럽트에 대해 이해한다.
서론
"운영체제(Operating System)"는 컴퓨터 하드웨어를 관리하는 소프트웨어이다.
운영체제는 응용 프로그램을 위한 기반을 제공하며 컴퓨터 사용자와 컴퓨터 하드웨어 사이에서 중재자 역할을 수행한다.
운영체제의 놀라운 점은 광범위한 컴퓨팅 환경에서 이러한 일들을 매우 다양한 방법으로 수행한다는 것이다.
운영체제는 "사물 인터넷(Inter-net of Things)"을 포함하는 자동차와 홈 기기에서 스마트폰, 개인용 컴퓨터, 대형 컴퓨터 및 클라우드 컴퓨팅 환경까지 어느 곳에나 존재한다.
현대 컴퓨팅 환경에서 운영체제의 역할을 탐구하기 위하여 먼저 컴퓨터 하드웨어의 구성과 구조를 이해하는 것이 중요하다.
이러한 지식에는 CPU, 메모리 및 입출력 장치와 저장장치가 포함된다.
운영체제의 근본적인 책임은 이러한 자원들을 프로그램에 할당하는 것이다.
운영체제는 덩치가 매우 크고 복잡하므로 부분별로 생성되어야 한다.
이 하나의 부분은 전체 시스템 윤곽에 잘 맞는 일부여야 하며 이 부분들의 입력과 출력, 동작은 주의를 기울여 정의해야한다.
이 장에서는 현대 컴퓨터 시스템의 주요 구성요소와 운영체제가 제공하는 기능에 대한 일반적인 개관을 제공한다.
또한 이 책의 나머지 부분을 위한 무대를 설정하는 데 필요한 다수의 주제, 운영체제에 사용되는 자료구조, 계산환경 및 공개 소스 및 무료 운영체제를 다룬다.
운영체제가 할 일 (What Operating Systems Do)
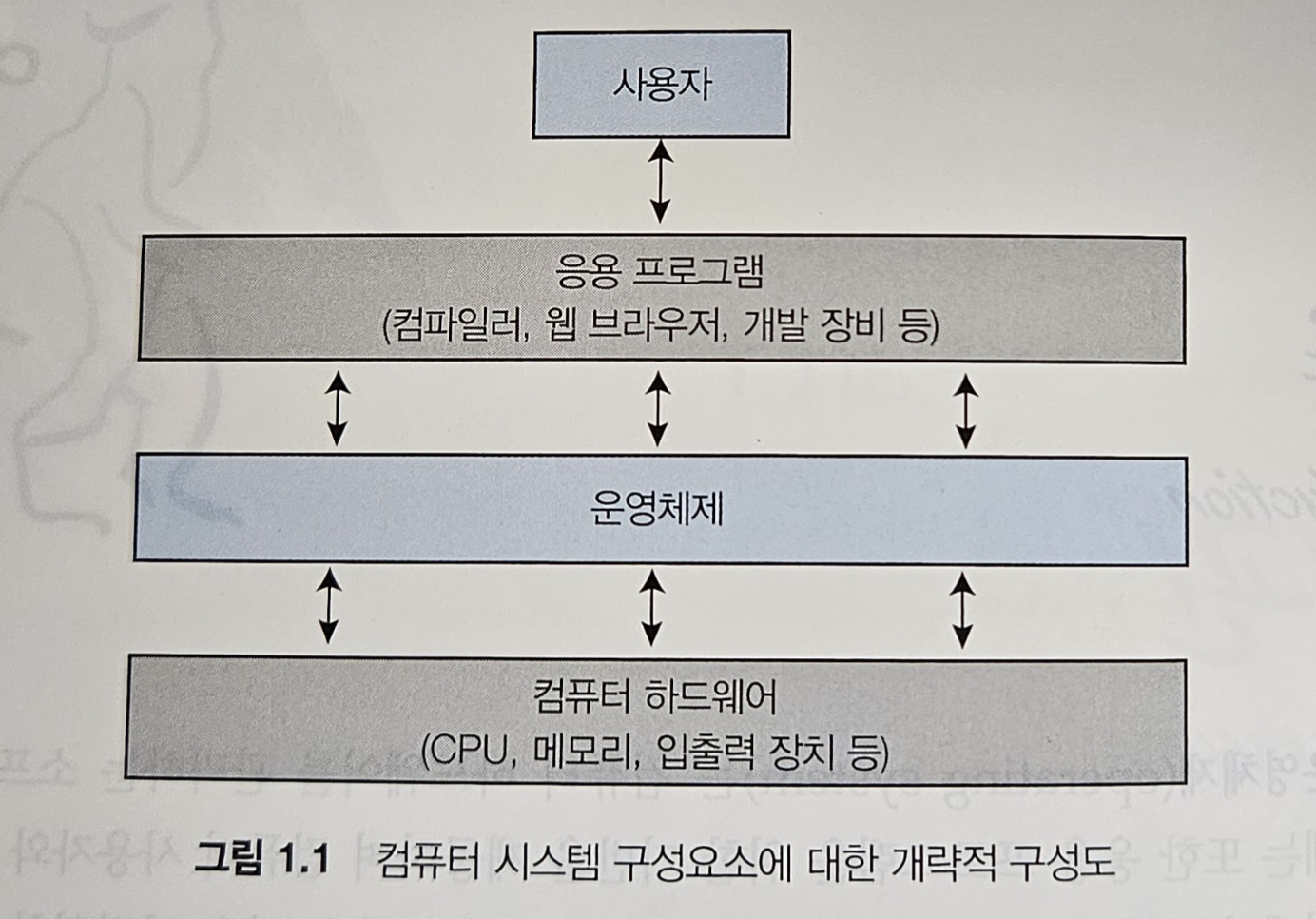
전체 컴퓨터 시스템에서 운영체제가 수행하는 역할에 대해 살펴보는 것으로 논의를 시작한다.
컴퓨터 시스템은 대개 네 가지 구성요소인 하드웨어, 운영체제, 응용 프로그램, 사용자로 구분할 수 있다(그림 1.1).
"하드웨어"는 중앙 처리 장치(CPU), 메모리 및 입출력(I/O) 장치로 구성되어, 기본 계산용 자원을 제공한다.
"응용 프로그램"인 워드 프로세서, 스프레드시트, 컴파일러, 웹 브라우저 등은 사용자의 계산 문제를 해결하기 위해 이들 자원이 어떻게 사용될지를 정의한다.
"운영체제"는 다양한 사용자를 위해 다양한 응용 프로그램 간의 하드웨어 사용을 제어하고 조정한다.
우리는 컴퓨터 시스템이 하드웨어, 소프트웨어 및 데이터로 구성되어 있다고 볼 수 있다.
운영체제는 컴퓨터 시스템이 동작할 때 이들 자원을 적절하게 사용할 수 있는 방법을 제공한다.
운영체제는 정부(government)와 유사하다.
운영체제는 정부처럼 그 자체로는 유용한 기능을 수행하지 못한다.
운영체제는 단순히 다른 프로그램이 유용한 작업을 할 수 있는 "환경"을 제공한다.
운영체제의 역할을 좀 더 완전히 이해하기 위하여 사용자와 시스템 두 관점에서 살펴본다.
사용자 관점
컴퓨터에 대한 사용자의 관점은 사용되는 인터페이스에 따라 달라진다.
많은 컴퓨터 사용자는 랩톱 혹은 모니터, 키보드, 마우스로 구성된 PC 앞에서 작업한다.
이러한 시스템은 한 사용자가 자원을 독점하도록 설계되었으며 목표는 사용자가 수행하는 작업(또는 놀이)을 최대화하는 것이다.
이러한 경우 운영체제는 대부분 "사용의 용이성"을 위해 설계되고 성능에 약간 신경을 쓰고 다양한 하드웨어와 소프트웨어 자원이 어떻게 공유되느냐의 "자원의 이용"에는 전혀 신경을 쓰지 않는다.
점점 더 많은 사용자가 스마트폰 및 테이블릿과 같은 모바일 장치(일부 사용자의 데스크톱 및 랩톱 컴퓨터 시스템을 대체하는 장치)와 상호 작용한다.
이러한 장치는 일반적으로 셀룰러 또는 기타 무선 기술을 통해 네트워크에 연결된다.
모바일 컴퓨터용 사용자 인터페이스는 일반적으로 사용자는 실제 키보드와 마우스를 사용하지 않고 화면에서 손가락을 누르고 스와이프하여 시스템과 상호 작용하는 "터치스크린"이 특징이다.
또한 많은 휴대 기기에서 사용자가 Apple의 "Shiri"와 같은 "음성 인식" 인터페이스를 통해 상호 작용 할 수 있다.
일부 컴퓨터는 사용자 관점이 존재하지 않거나 매우 작은 예도 있다.
예를 들면, 가전제품이나 자동차 내의 "내장형 컴퓨터"는 숫자 키패드를 가지고, 상태를 보이기 위해 표시등을 켜고 끌 수 있지만 이들 컴퓨터나 운영체제와 응용 프로그램은 사용자의 개입 없이 작동하도록 설계되어 있다.
시스템 관점
컴퓨터의 관점에서 운영체제는 하드웨어와 가장 밀접하게 연관된 프로그램이다.
따라서 우리는 운영체제를 자원 할당자(resource allocator)로 볼 수 있다.
컴퓨터 시스템은 문제를 해결하기 위해 요구되는 여러 가지 자원들(하드웨어와 소프트웨어), 즉 CPU 시간, 메모리 공간, 저장장치 공간, 입출력 장치 등을 가진다.
운영체제는 이들 자원의 관리자로서 동작한다.
자원에 대해 서로 상충할 수도 있는 많은 요청이 있으므로, 운영체제는 컴퓨터 시스템을 효율적이고 공정하게 운영할 수 있도록 어느 요청에 자원을 할당할지를 결정해야 한다.
운영체제에 대한 다소 다른 관점은 여러 가지 입출력 장치와 사용자 프로그램을 제어할 필요성을 강조한다.
운영체제는 제어 프로그램(control program)이다.
제어 프로그램은 컴퓨터의 부적절한 사용을 방지하기 위해 사용자 프로그램의 수행을 제어한다.
운영체제는 특히 입출력 장치의 제어와 작동에 깊이 관여한다.
운영체제의 정의
일반적으로 운영체제에 대한 적합한 정의는 없다.
운영체제는 유용한 컴퓨팅 시스템을 만드는 문제를 해결할 수 있는 합리적인 방법을 제공하기 때문에 존재한다.
컴퓨터 시스템의 기본 목표는 프로그램을 실행하고 사용자 문제를 더욱 쉽게 해결할 수 있게 하는 것이다.
컴퓨터 하드웨어는 이 목표를 가지고 구성된다.
이러한 프로그램에는 입출력 장치 제어와 같은 특정 공통 작업이 필요하다.
자원을 제어하고 할당하는 일반적인 기능은 운영체제라는 하나의 소프트웨어로 통합된다.
또한 운영체제에 포함되는 요소에 보편적인 정의는 없다.
단순한 관점은 "운영체제"를 주문할 때 공급 업체가 제공하는 모든 것을 포함한다는 것이다.
그러나 포함된 기능은 시스템마다 크게 다르다.
일부 시스템은 메가바이트 미만의 공간을 차지하고 전체 화면 편집기가 없는 반면, 다른 시스템은 기가바이트의 공간이 필요하며 그래픽 윈도 시스템을 기반으로 한다.
더욱 일반적인 정의와 우리가 지지하는 것은 운영체제가 컴퓨터에서 항상 실행되는 프로그램(일반적으로 "커널"이라고 함)이다.
커널과 함께 두 가지 다른 유형의 프로그램이 있다.
운영체제와 관련되어 있지만 반드시 커널의 일부일 필요는 없는 "시스템 프로그램"과 시스템 작동과 관련되지 않은 모든 프로그램을 포함하는 응용 프로그램이다.
운영체제에는 항상 실행 중인 커널, 응용 프로그램 개발을 쉽게 하고 기능을 제공하는 미들웨어 프레임워크 및 시스템 실행 중에 시스템을 관리하는 데 도움이 되는 시스템 프로그램이 포함된다.
왜 운영체제를 공부하는가?
컴퓨터 과학에 종사하는 사람은 많지만 운영체제를 만들거나 수정하는 데는 소수만이 참여한다.
그렇다면 왜 운영체제와 그들의 작동방식을 공부하는가?
단순하게 거의 모든 코드가 운영체제 위해서 실행되므로 운영체제 작동방식에 대한 지식은 적절하고 효율적이며 효과적이며 안전한 프로그래밍에 중요하기 때문이다.
운영체제의 기본 지식, 컴퓨터 하드웨어 구동 방식 및 응용 프로그램에 제공하는 내용을 이해하는 것은 운영체제를 작성하는 사람들에게 필수적일 뿐만 아니라 그 위에서 프로그램을 작성하고 운영체제를 사용하는 사람들에게도 매우 유용한다.
컴퓨터 시스템의 구성(Computer System Org)
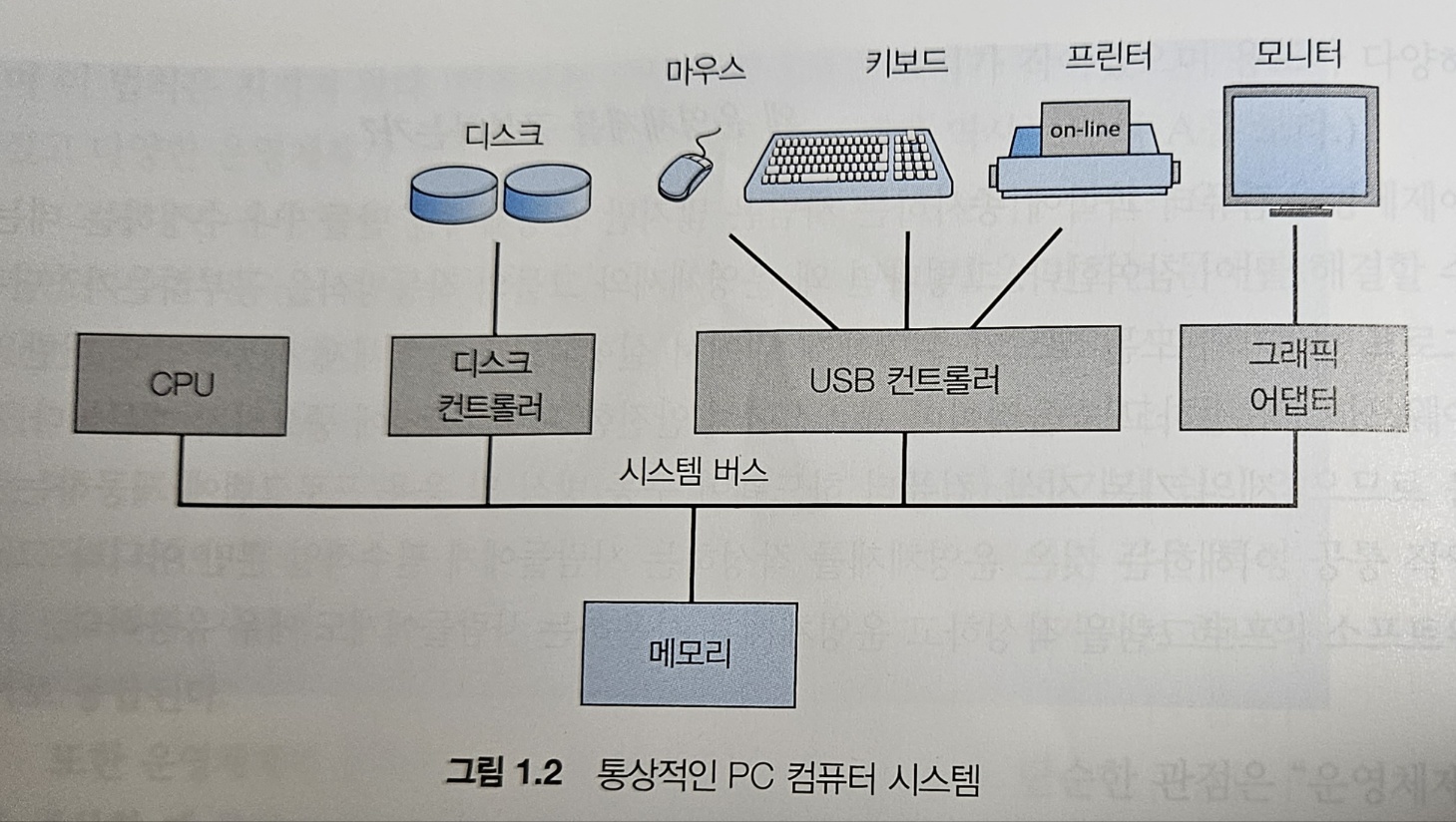
현대의 범용 컴퓨터 시스템은 하나 이상의 CPU와 구성요소와 공유 메모리 사이의 엑세스를 제공하는 공통 버스를 통해 연결된 여러 장치 컨트롤러로 구성된다(그림 1.2)
각 장치 컴트롤러는 특정 유형의 장치(예: 디스크 드라이브, 오디오 장치 또는 그래픽 디스플레이)를 담당한다.
컨트롤러에 따라 둘 이상의 장치가 연결될 수도 있다.
예를 들어 하나의 시스템 USB 포트는 여러 장치를 연결할 수 있는 USB 허브에 견결할 수 있다.
장치 컨트롤러는 일부 로컬 버퍼 저장소와 특수 목적 레지스터 집합을 유지 관리한다.
장치 컨트롤러는 제어하는 주변 장치와 로컬 버퍼 저장소 간에 데이터를 이동한다.
일반적으로 운영체제에는 각 장치 컨트롤러마다 장치 드라이버가 있다.
이 장치 드라이버는 장치 컨트롤러의 작동을 잘 알고 있고 나머지 운영체제에 장치에 대한 일관된 인터페이스를 제공한다.
CPU와 장치 컨트롤러는 병렬로 실행되어 메모리 사이클을 놓고 경쟁한다.
공유 메모리를 질서 있게 액세스하기 메모리 컨트롤러는 메모리에 대한 엑세스를 동기화한다.
다음 절에서는 시스템의 세 가지 주요 측면에 중점을 두어 이러한 시스템의 작동방식의 기본 사항에 관해 설명한다.
CPU의 조치가 필요한 이벤트에 대해 경고하는 이터럽트부터 살펴볼 것이다.
그런 다음 저장장치 구조 및 입출력 구조에 관해 알아보자.
인터럽트
일반적인 컴퓨터 작업(입출력을 수행하는 프로그램)을 고려하자.
입출력 작업을 시작하기 위해 장치 드라이버는 장치 컨트롤러의 적절한 레지스터에 값을 적재한다.
그런 다음 장치 컨트롤러는 이러한 레지스터의 내용을 검사하여 수행할 작업을(예: "키보드에서 문자 읽기") 결정한다.
컨트롤러는 장치에서 로컬 버퍼로 데이터 전송을 시작한다.
데이터 전송이 완료되면 장치 컨트롤러는 장치 드라이버에게 작업이 완료되었음을 알린다.
그런 다음 장치 드라이버는 읽기 요청이면 데이터 또는 데이터에 대한 포인터를 반환하며 운영체제의 다른 부분에 제어를 넘긴다.
다른 작업에 경우 장치 드라이버는 "쓰기 완료" 또는 "장치 사용 중"과 같은 상태 정보를 반환한다.
그러나 컨트롤러는 장치 드라이버에게 작업을 완료했다는 사실을 어떻게 알리는가?
이는 "인터럽트"를 통해 이루어진다.
인터럽트 개요
하드웨어는 어느 순간이든 시스템 버스를 통해 CPU에 신호를 보내 인터럽트를 발생시킬 수 있다. (컴퓨터 시스템에는 많은 버스가 있을 수 있지만 시스템 버스는 주요 구성요소 사이의 주요 통신 경로이다.)
인터럽트는 다른 많은 목적으로도 사용되며 운영체제와 하드웨어의 상호 작용 방식의 핵심 부분이다.
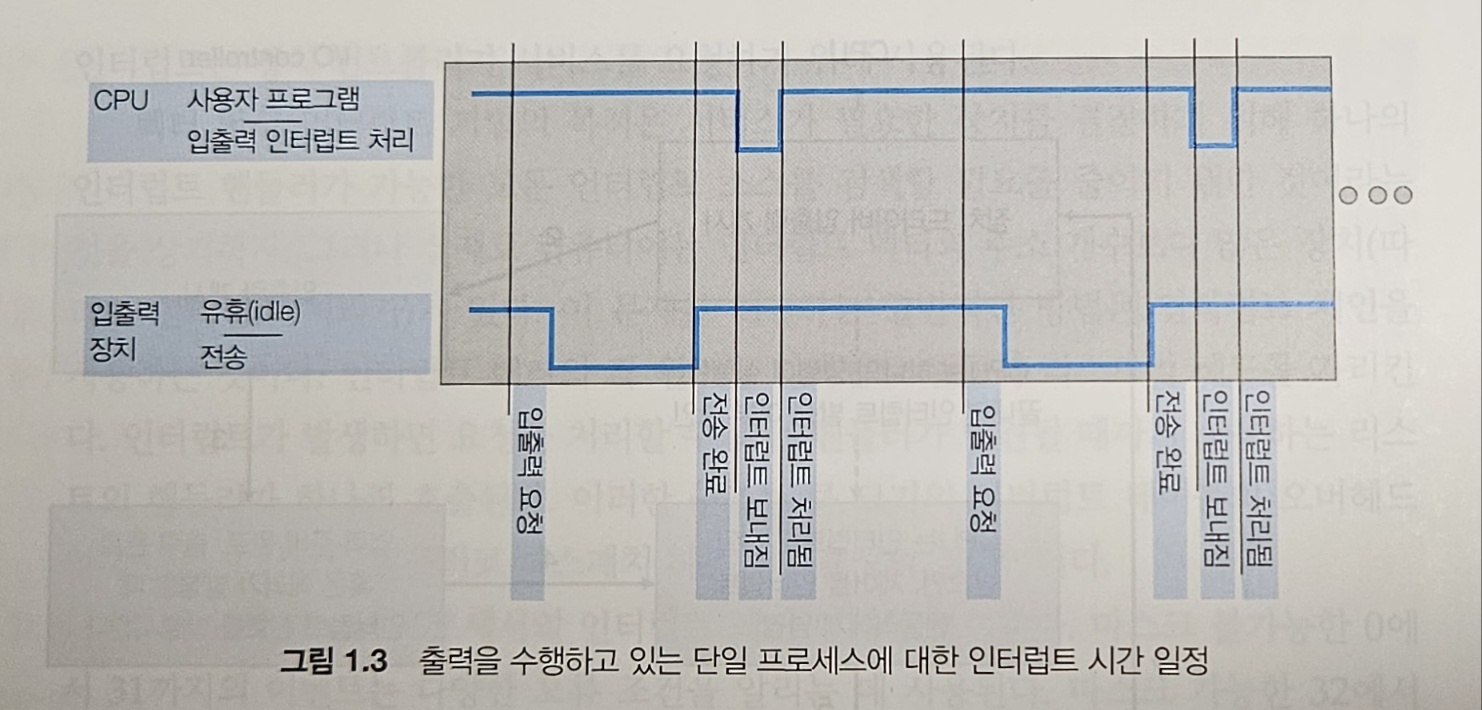
CPU가 인터럽트 되면, CPU는 하던 일을 중단하고 즉시 고정된 위치로 실행을 옮긴다.
이러한 고정된 위치는 일반적으로 인터럽트를 위한 서비스 루틴이 위치한 시작 주소를 가지고 있다.
그리고 인터럽트는 서비스 루틴이 실행된다.
인터럽트 서비스 루틴의 실행이 완료되면, CPU는 인터럽트 되었던 연산을 재개한다.
이러한 연산의 시간 일정이 그림 1.3에 있다.
인터럽트는 컴퓨터 구조의 중요한 부분이다.
각 컴퓨터 설계는 자신의 인터럽트 메커니즘을 가지고 있으며, 몇 가지 기능은 공통적이다.
인터럽트는 적절한 서비스 루틴으로 제어를 전달한다.
이러한 전달을 관리하는 직선적인 방법은 인터럽트 정보를 조사하는 일반적인 루틴을 호출하는 방법이다.
이 루틴은 이어 인터럽트 고유의 핸들러를 호출한다.
그러나, 인터럽트는 매우 빈번하게 발생하기 때문에 빠르게 처리되어야 한다.
필요한 속도를 제공하기 위해 인터럽트 루틴에 대한 포인터들의 테이블을 대신 이용할 수 있다.
이 경우 중간 루틴을 둘 필요 없이, 테이블을 통하여 간접적으로 인터럽트 루틴이 호출될 수 있다.
일반적으로 포인터들의 테이블은 하위 메모리에 저장된다(첫 100개 정도의 위치).
이들 위치에는 여러 장치에 대한 인터럽트 서비스 루틴의 주소가 들어 있다.
인터럽트가 요청되면, 인터럽트를 유발한 장치를 위한 인터럽트 서비스 루틴의 주소를 제공하기 위해 이 주소의 배열, 즉 "인터럽트 벡터"가 인터럽트 요청과 함께 주어진 고유의 유일한 장치 번호로 색인된다.
Windows나 UNIX 같은 서로 다은 운영체제가 이러한 방법으로 인터럽트를 처리한다.
인터럽트 구조는 또한 인터럽트 된 모든 정보를 저장해야 인터럽트를 처리한 후 이 정보를 복원할 수 있다.
만약 인터럽트 루틴은 반드시 명시적으로 현재의 상태를 저장하여야 하며, 복귀하기 전에 상태를 복원해야 한다.
인터럽트를 서비스한 후, 저장되어 있던 복귀 주소를 프로그램을 카운터에 적재하고, 인터럽트에 의해 중단되었던 연산이 인터럽트가 발생되지 않았던 것처럼 다시 시작된다.
인터럽트 구현
기본 인터럽트 매커니즘은 다음과 같이 작동한다.
CPU 하드웨어에는 "인터럽트 요청 라인"이라는 선이 있는데, 이는 하나의 명령어의 실행을 완료할 때마다 CPU가 이 선을 감지한다.
CPU가 컨트롤러가 인터럽트 요청 라인에 신호를 보낸 것을 감지하면, 인터럽트 번호를 읽고 이 번호를 인터럽트 벡터의 인덱스로 사용하여 "인터럽트 핸들러 루틴"으로 점프한다.
그런 다음 해당 인덱스와 관련된 주소에서 실행을 시작한다.
인터럽트 처리기는 작업 중에 변경될 상태를 저장하고, 인터럽트 원인을 확인하고, 필요한 처리를 수행하고, 상태 복원을 수행하고, return_from_interrupt 명령어를 실행하여 CPU를 인터럽트 전 실행 상태로 되돌린다.
장치 컨트롤러가 인터럽트 요청 라인에 신호를 선언하여 인터럽트를 "발생(raise)" 시키고 CPU는 인터럽트를 "포착(catch)"하여 인터럽트 핸들러로 "디스패치(dispatch)"하고 핸들러는 장치를 서비스하여 인터럽트를 "지운다(clear)".
그림 1.4는 인터럽트-구동 입출력 사이클을 요약한 것이다.
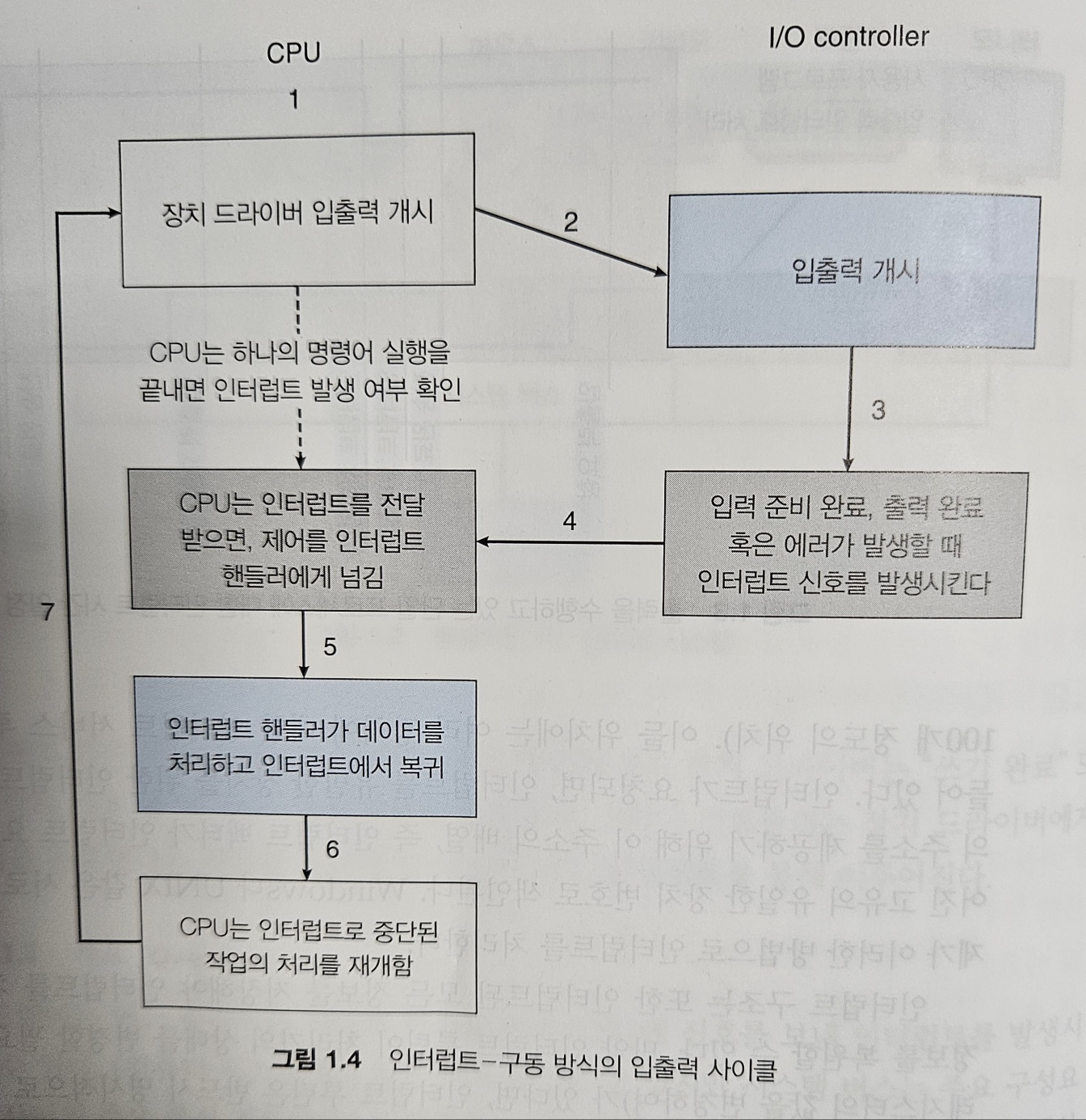
방금 설명한 기본 인터럽트 기법은 장치 컨트롤러가 서비스할 준비가 될 때와 같은 비동기 이벤트에 CPU가 대응할 수 있게 한다.
그러나 최신 운영체제에서는 더욱 정교한 인터럽트 처리 기능이 필요하다.
- 중요한 처리 중에 인터럽트 처리를 연기할 수 있어야한다.
- 장치의 적절한 인터럽트 핸들러로 효율적으로 디스패치 할 방법이 필요하다.
- 운영체제가 우선순위가 높은 인터럽트와 우선순위가 낮은 인터럽트를 구분하고 적절한 긴급도로 대응할 수 있도록 다단계 인터럽트가 필요하다.
최신 컴퓨터 하드웨어에서는 이 세가지 기능은 CPU 및 "인터럽트 컨트롤러 하드웨어"에 의해 제공된다.
대부분의 CPU에는 2개의 인터럽트 요청 라인이 있다.
하나는 복구할 수 없는 메모리 오류와 같은 이벤트를 위해 예약된 "마스크 불가능 인터럽트"이다.
두 번째 인터럽트 라인은 "마스킹 가능"이다.
인터럽트 되어서는 안된는 중요한 명령 시퀀스를 실행하기 전에 CPU에 의해 꺼질 수 있다.
마스킹 가능한 인터럽트는 장치 컨트롤러가 서비스를 요청하기 위해 사용된다.
벡터 방식 인터럽트 기법의 목적은 서비스가 필요한 장치를 결정하기 위해 하나의 인터럽트 핸들러가 가능한 모든 인터럽트 소스를 검색할 필요를 줄이기 위한 것이다.
그러나 실제로 컴퓨터에는 인터럽트 벡터의 주소 개수보다 많은 장치(따라서 인터럽트 처리기)가 있다.
이 문제를 해결하는 일반적인 방법은 "인터럽트 체인"을 사용하는 것이다.
인터럽트 벡터의 각 원소는 인터럽트 핸들러 리스트의 헤드를 가리킨다.
인터럽트가 발생하면 요청을 처리할 수 있는 핸들러가 발견될 때까지 상응하는 리스트의 핸들러가 하나씩 호출된다.
이러한 구조는 큰 크기의 인터럽트 테이블의 오버헤드와 하나의 인터럽트 핸들러로 디스패치하는 비효율성의 절충안이다.
그림 1.5는 intel 프로세서의 인터럽트 벡터 설계를 보여준다.
마스크 불가능한 0에서 31까지의 이벤트는 다양한 오류 조건을 알리는 데 사용된다.
마스크 가능한 32에서 255까지의 이벤트는 장치가 생성한 인터럽트 같은 그 외 인터럽트를 처리하기 위해 사용된다.

인터럽트 기법은 또한 인터럽트 "우선순위 레벨"을 구현한다.
이러한 레벨을 통해 CPU는 모든 인터럽트를 마스킹하지 않고도 우선순위가 낮은 인터럽트를 처리를 연기할 수 있고, 우선순위가 높은 인터럽트가 우선순위가 낮은 인터럽트의 실행을 선점할 수 있다.
요약하면, 인터럽트는 최신 운영체제에서 비동기 이벤트를 처리하기 위해 사용된다(다른 목적으로 사용되는 것에 관해서는 추후에 학습).
장치 컨트롤러 및 하드웨어에 오류로 인해 인터럽트가 발생한다.
가장 긴급한 작업을 먼저 수행하기 위해 최신 컴퓨터는 인터럽트 우선순위 시스템을 사용한다.
인터럽트는 시간에 민감한 처리에 빈번하게 사용되므로 시스템 성능을 좋게 하려면 효율적인 인터럽트 처리가 필요하다.